How to get NVIDIA LLM, AI and ML optimized VM on GCP
This section describes how to provision and connect to NVIDIA LLM, AI and ML optimized VM on GCP.
- Open NVIDIA LLM, AI and ML optimized VM listing on GCP Marketplace
- Click Get Started.
-
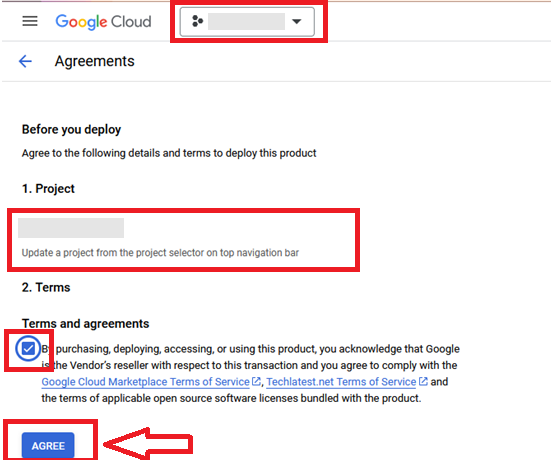
It will take you to the agreement page. On this page, you can change the project from the project selector on top navigator bar as shown in the below screenshot.
-
Accept the Terms and agreements by ticking the checkbox and clicking on the AGREE button.
-
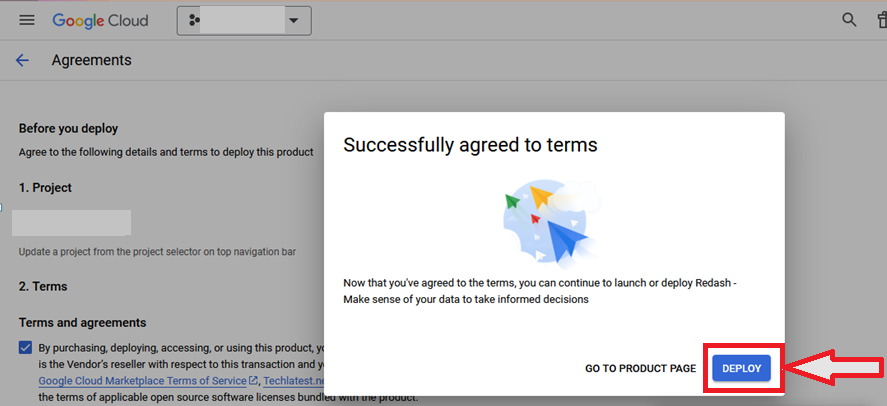
It will show you the successfully agreed popup page. Click on Deploy.
-
On deployment page, give a name to your deployment.
- In Deployment Service Account section, click on Existing radio button and Choose a service account from the Select a Service Account dropdown.
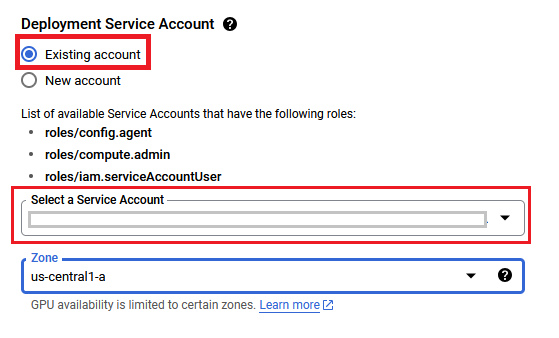
- If you don't see any service account in dropdown, then change the radio button to New Account and create the new service account here.
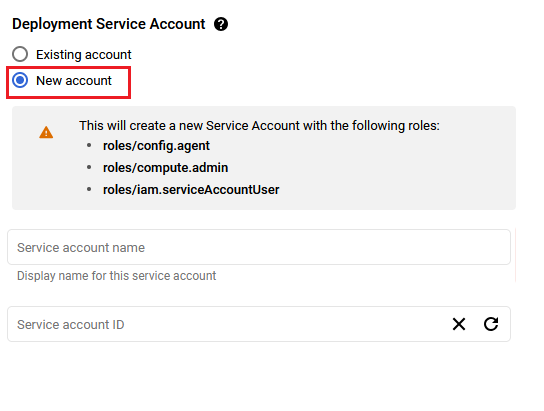
- If after selecting New Account option, you get below permission error message then please reach out to your GCP admin to create service account by following Step by step guide to create GCP Service Account and then refresh this deployment page once the service account is created, it should be available in the dropdown.
You are missing resourcemanager.projects.setIamPolicy permission, which is needed to set the required roles on the created Service Account
- Select a zone where you want to launch the VM(such as us-east1-a)
- Optionally change the number of cores and amount of memory. ( This defaults to 2 vCPUs and 7.5 GB ram)
- The VM can only be deployed with the NVIDIA GPU instance. You can change the Type and number of GPUs from the dropdown. (This defaults to 1 NVIDIA T4 GPU )
Note: GPU availability is limited to certain zones.
NOTE: While deploying the instance on GPU, if you encounter the quota exhaust error or you are unable to deploy the instance on GPU VM then please refer to our Request Quota on Google Cloud Platform
- Optionally change the boot disk type and size. (This defaults to ‘Standard Persistent Disk’ and 45 GB respectively)
- Optionally change the network name and subnetwork names. Be sure that whichever network you specify has ports 22 (for ssh), 3389 (for RDP) and 443 (for HTTPS) exposed.
- Click Deploy when you are done.
- NVIDIA LLM, AI and ML optimized VM will begin deploying.

-
A summary page displays when the compute engine is successfully deployed. Click on the Instance link to go to the instance page .
-
On the instance page, click on the “SSH” button, select “Open in browser window”.
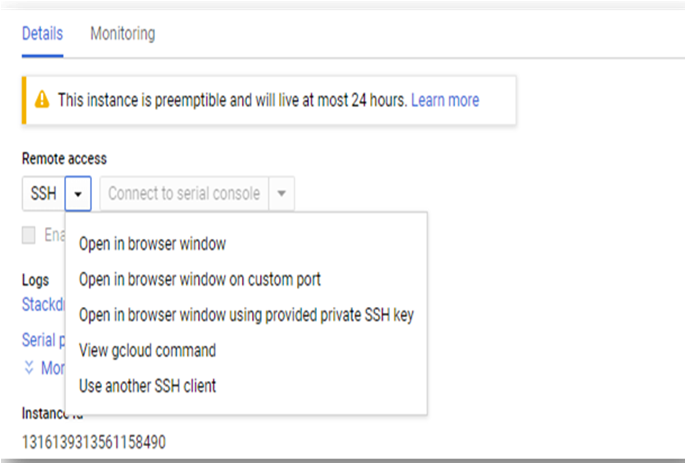
- This will open SSH window in a browser.
- Run below command to set the password for “ubuntu” user
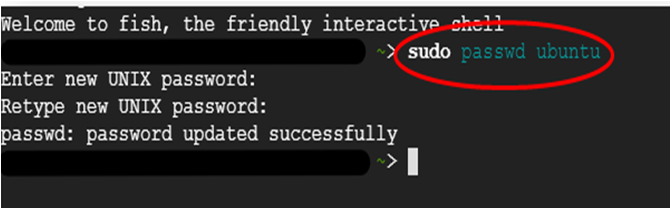
-
Now the password for ubuntu user is set, you can connect to the VM’s desktop environment from any local windows machine using RDP or linux machine using Remmina.
-
To connect using RDP via Windows machine, first note the external IP of the VM from VM details page as highlighted below
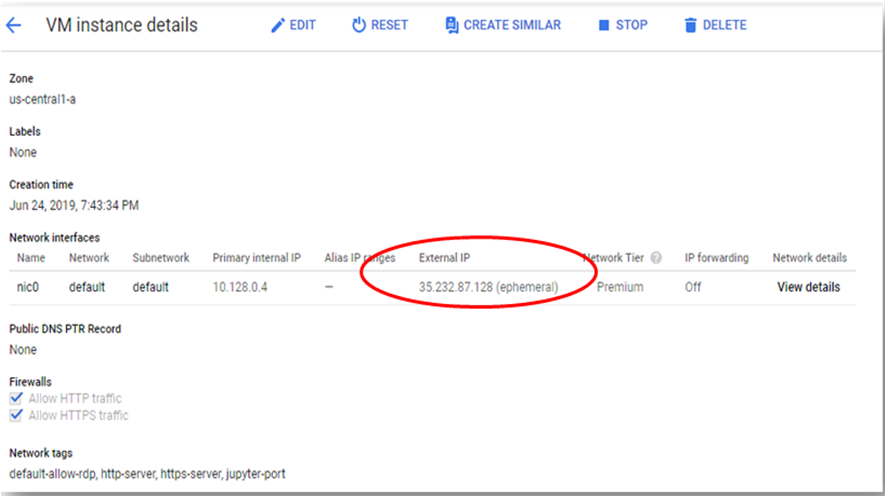
-
Then From your local windows machine, goto “start” menu, in the search box type and select “Remote desktop connection”
-
In the “Remote Desktop connection” wizard, paste the external ip and click connect
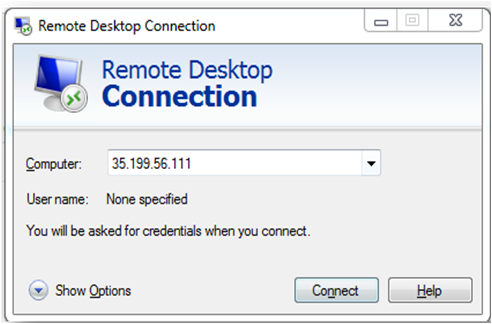
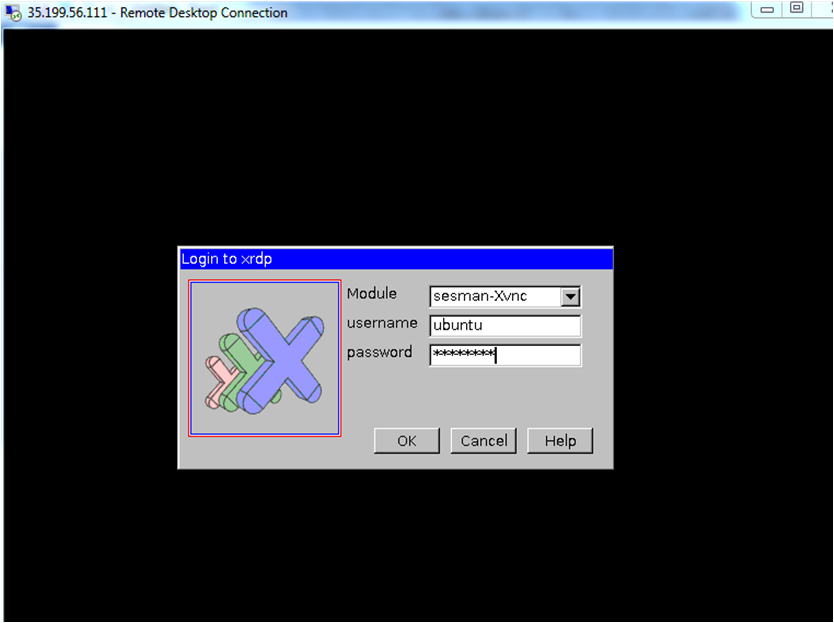
- This will connect you to the VM’s desktop environment. Provide “ubuntu” as the userid and the password set in step 6 to authenticate. Click OK
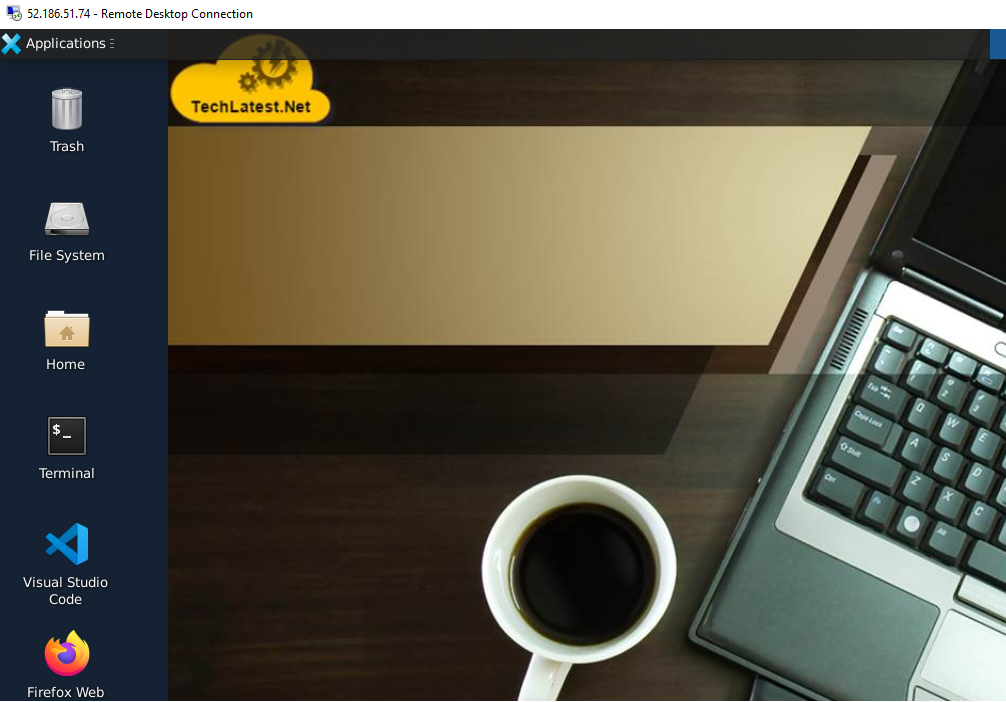
- Now you are connected to out of box NVIDIA LLM, AI and ML optimized VM environment via Windows machines.
-
To connect using RDP via Linux machine, first note the external IP of the VM from VM details page,then from your local Linux machine, goto menu, in the search box type and select “Remmina”.
Note: If you don’t have Remmina installed on your Linux machine, firstInstall Remmina as per your linux distribution.
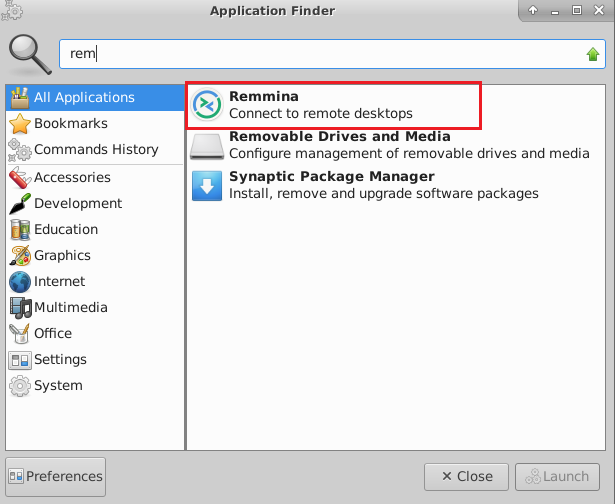
- In the “Remmina Remote Desktop Client” wizard, select the RDP option from dropdown and paste the external ip and click enter.
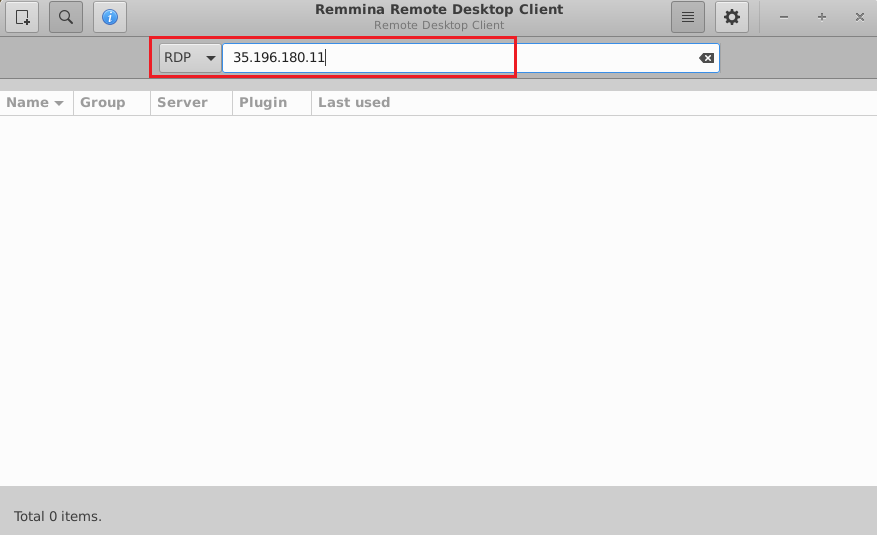
- This will connect you to the VM’s desktop environment. Provide “ubuntu” as the userid and the password set in step 6 to authenticate. Click OK
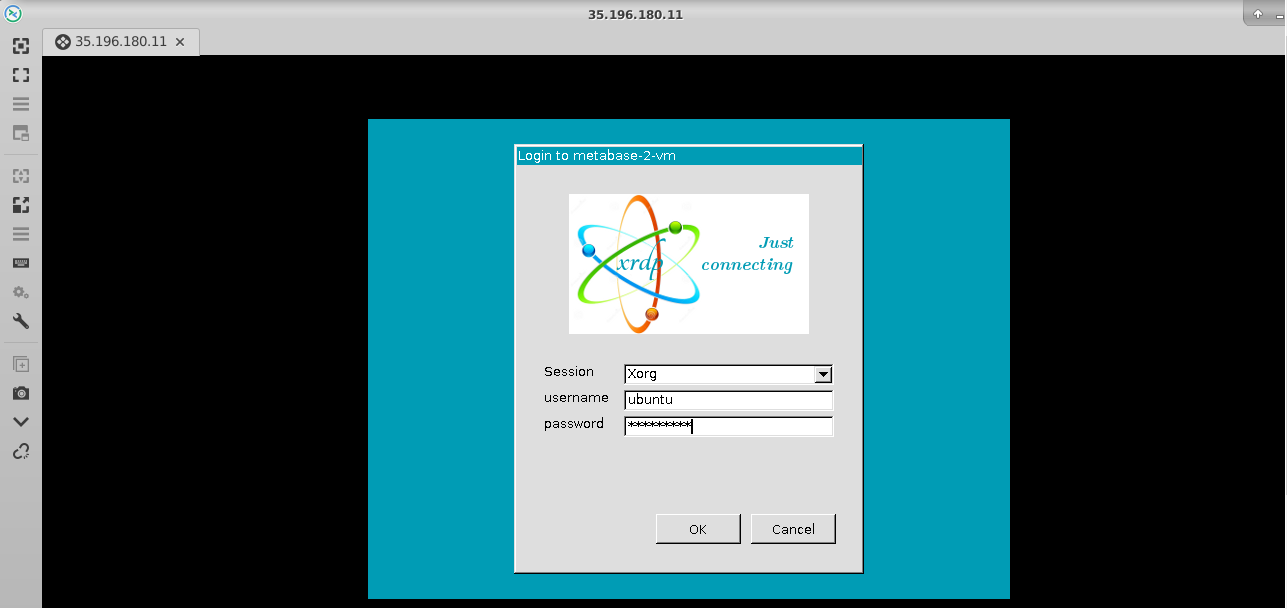
- Now you are connected to out of box NVIDIA LLM, AI and ML optimized VM environment via Linux machine.
- You can use the remote desktop you connected in above step for using the VM, however, more convenient and better method is to use the Jupyter/Ipython notebook which comes with the VM .
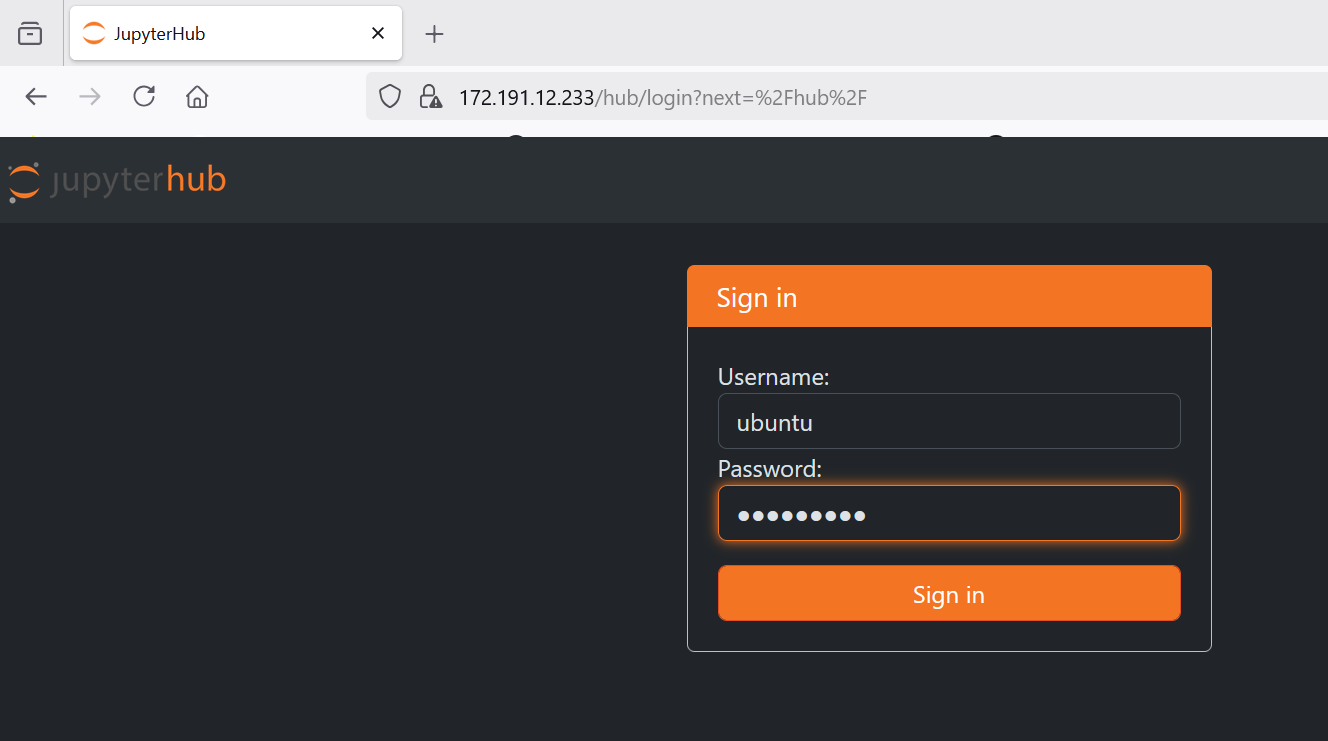
The Notebook is available on the same public IP you used for remote desktop and accessible via any browser. Just open the browser and type the public IP address and you will get below screen for login .
The Jupyter Notebook is configured with the ubuntu as an admin user. Login with ubuntu as username and use a ubuntu user password set in the above step 6.
Note: Make sure you use “https” and not “http” in the url. Browser will display SSL Certificate warning. Accept and proceed to Jupyter hub login page.
- After Login , you will see below screen. This is JupyterLab. You will find various options here. You can Access Jupyter Notebook, Console, Files and Folders, etc.
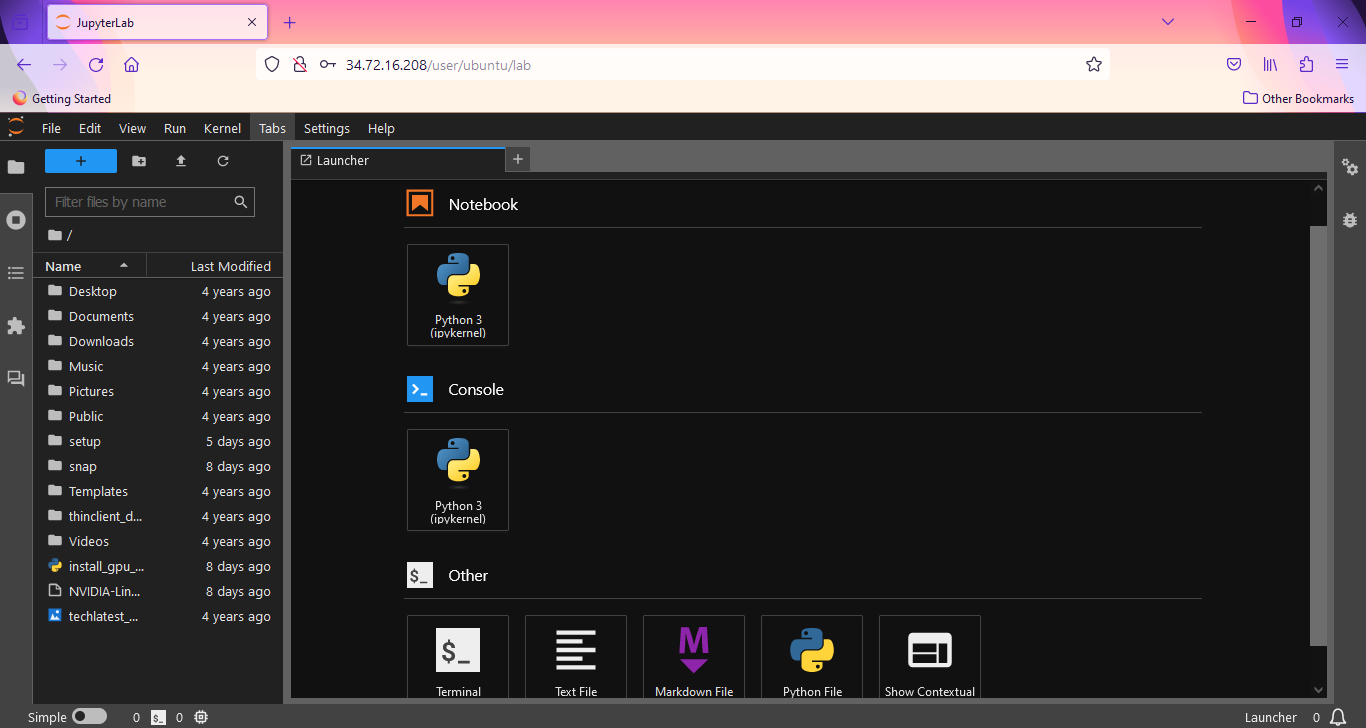
- This VM comes with the JuputerAI plugin installed out of the box which allow you to access Chat UI in the JupyterLab. This can be used for AI-conversation with lots of LLMs via APIs. It has support for chatgpt and lots of other LLMs.
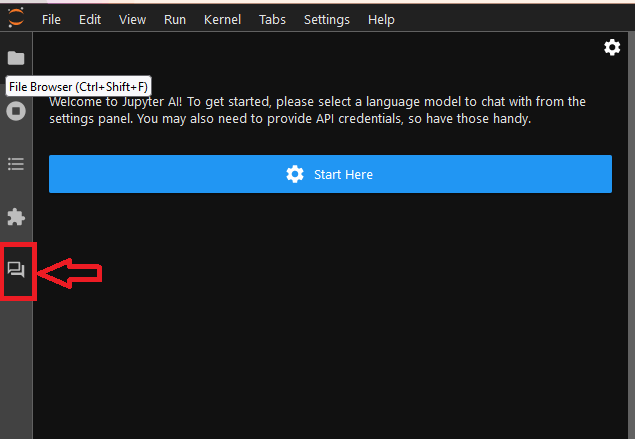
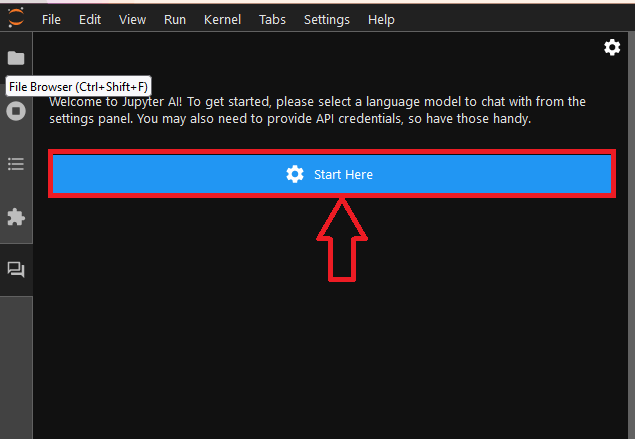
- To configure your Jupyternaut(ChatUI official name), You need to select a language model and an embedding model to chat. Once you have made your selections, the UI may display text boxes for one or more settings keys. So keep your keys ready with you. click on Start Here.
- Select a Language Model and Embedding model from the dropdown. If your selected model needs API keys, provide the API Keys. You need to get the API keys from the selected model providers.
For example, for OpenAI provider you can get the API keys as explained here.
Select the Input Type.
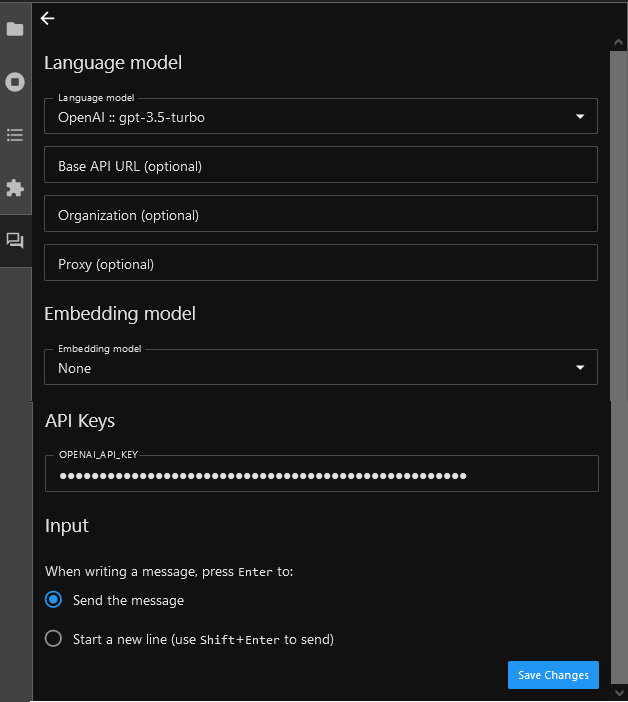
- Click on Save Changes. Once settings are saved successfully, click the “back” (left arrow) button in the upper-left corner of the Jupyter AI side panel. The chat interface now appears.
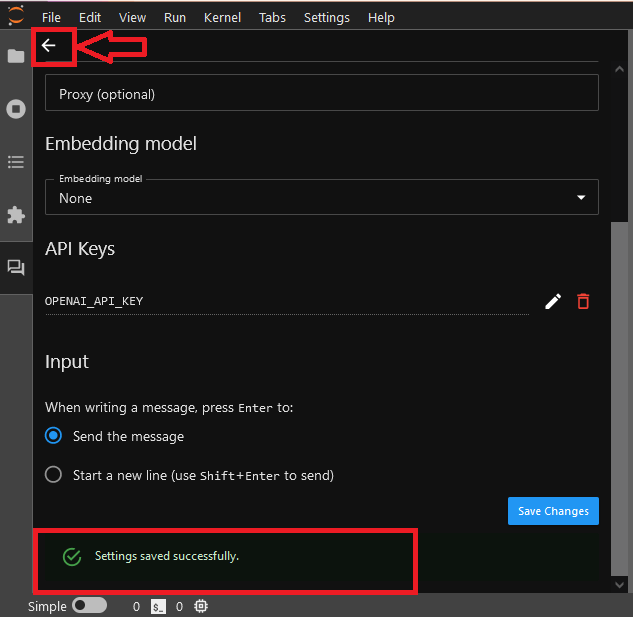
- Now your personal assistance is ready. Seek code suggestions, debugging tips, or even have code snippets generated for you by interacting with the chat UI.
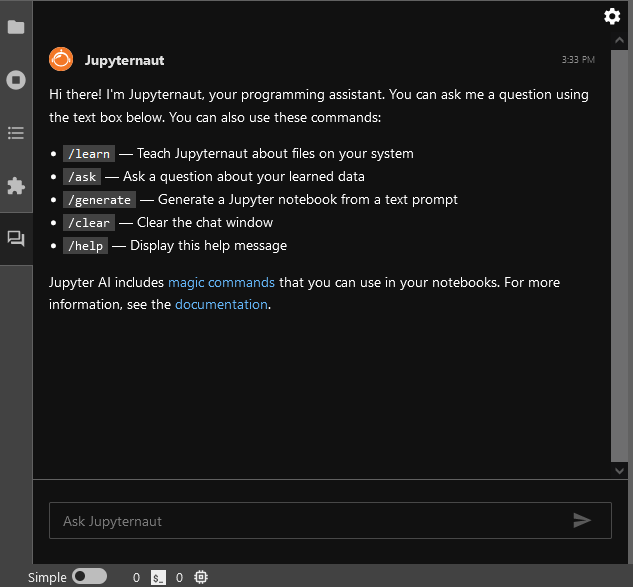
For more details on how to use Chat UI , please refer The chat interface Documentations.
- This VM also comes with the magics package jupyter_ai_magics installed out of the box. These magic commands %%ai and %ai turns your Jupyter into a generative AI playground anywhere the IPython kernel runs.
Before you send your first prompt to an AI model, load the IPython extension by running the following code in a notebook cell or IPython shell: -
%load_ext jupyter_ai_magics
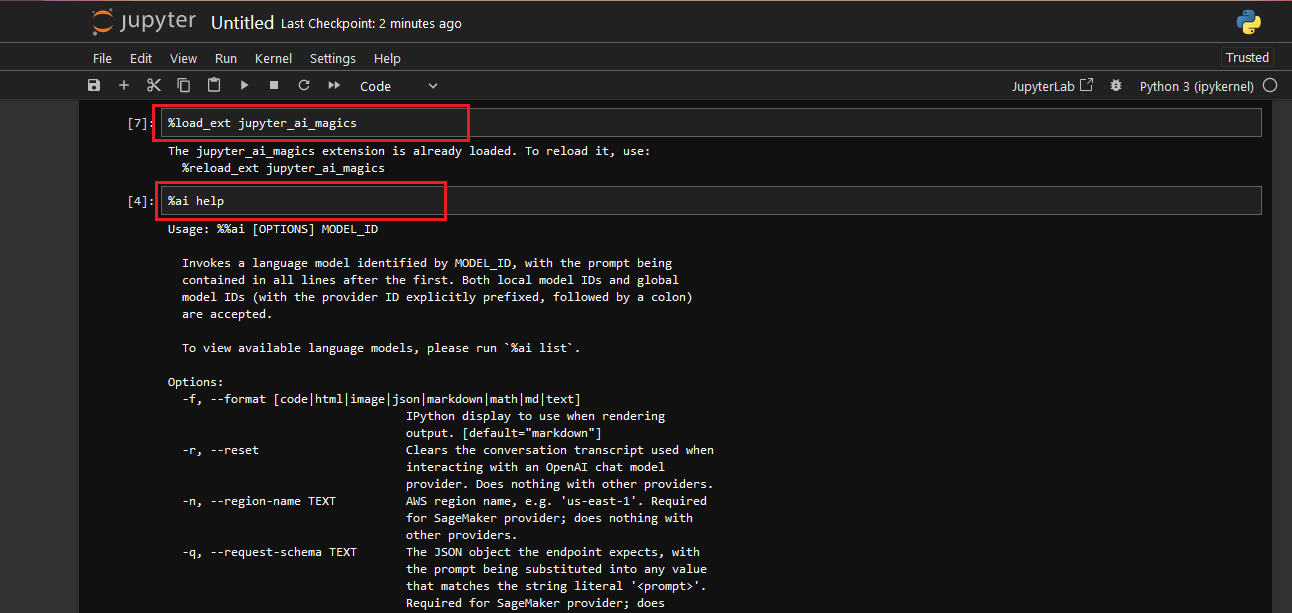
To use these magic commands, open Jupyter Notebook. Run %ai help for help with syntax.
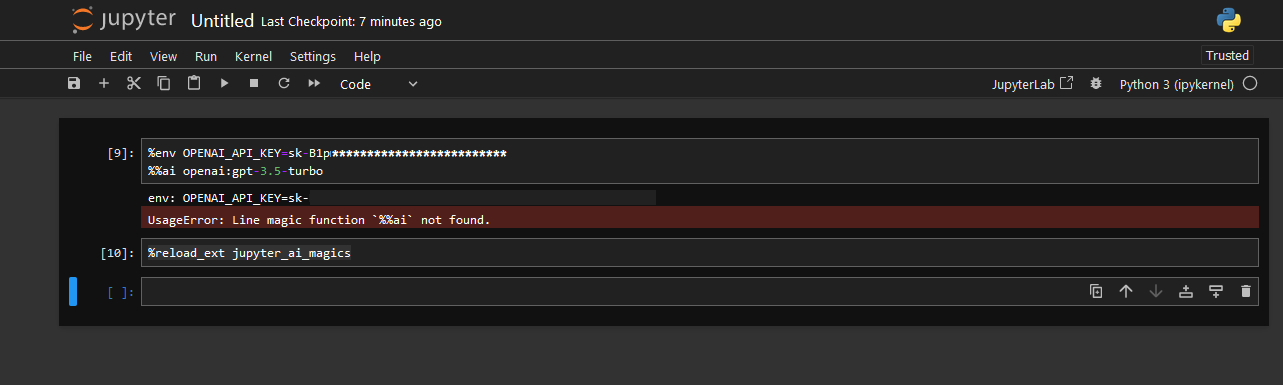
- The %%ai cell magic allows you to invoke a language model of your choice with a given prompt.The model is identified with a global model ID, which is a string with the syntax provider-id:local-model-id, where provider-id is the ID of the provider and local-model-id is the ID of the model scoped to that provider Set your model API keys using environment variable and your model of choice as shown below. Reload the IPython extension.
%env OPENAI_API_KEY=Your API Key
%%ai <provider-id>:<local-model-id>
%reload_ext jupyter_ai_magics
- Now you can invoke a model as follows. The prompt begins on the second line of the cell.
%%ai model
Your prompt here
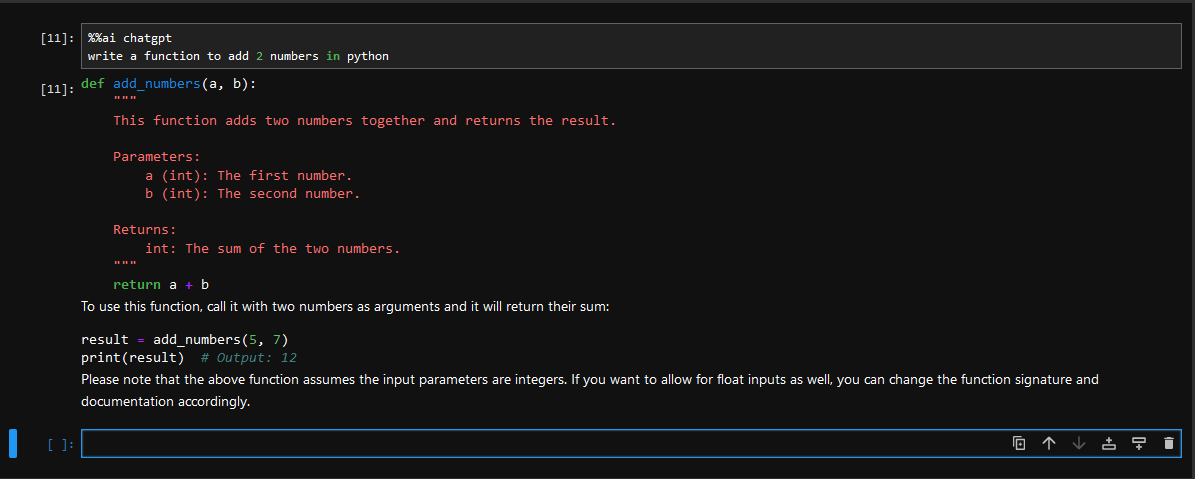
- Jupyter AI also includes multiple subcommands, which may be invoked via the %ai line magic.
The %ai list subcommand prints a list of available providers and models.
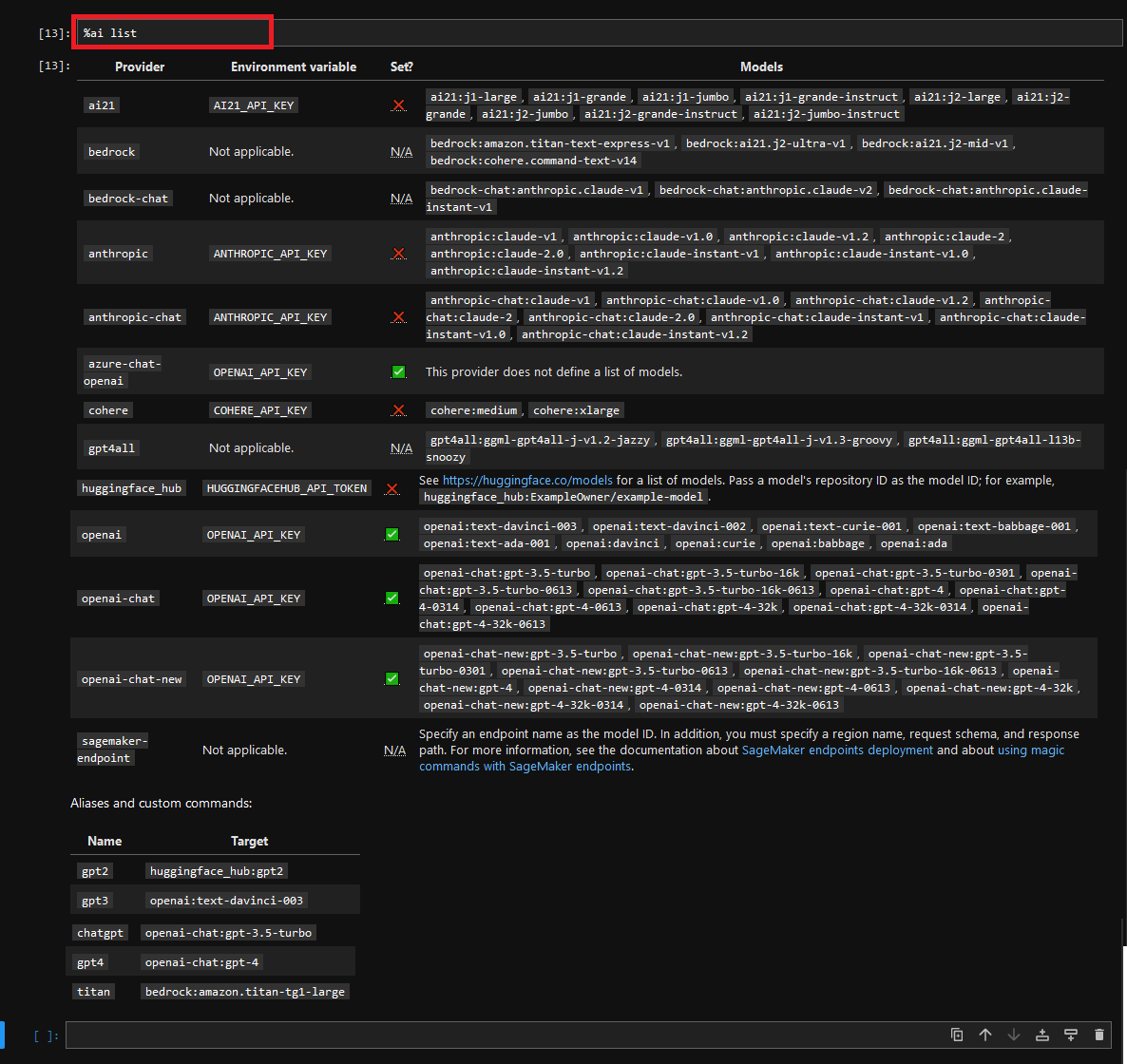
Please refer The %ai and %%ai magic commands Documentations for more details.
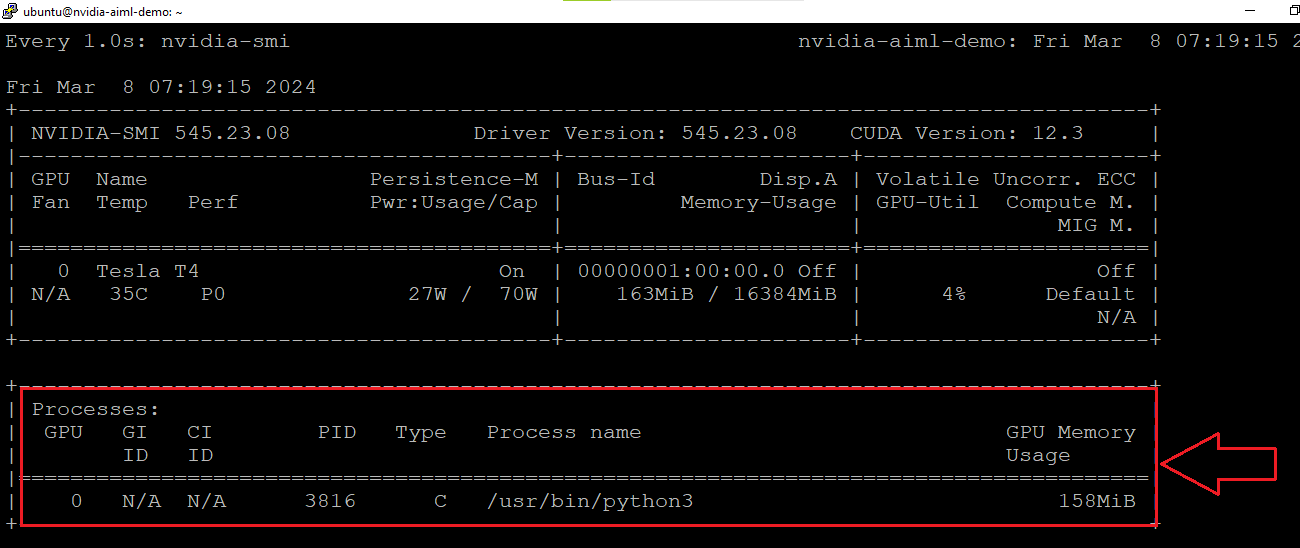
- You can check if NVIDIA GPU is being used by AIML code. For that connect to VM via terminal and run watch -n 1 nvidia-smi . This will continuously monitor nvidia-smi output and update it every 1 second. Initially, it will show no processes utilizing nvidia gpu in the output. Keep the watch command running. Open the jupyter Notebook and run the some cuda code. Check the watch command output and it should show you the python process running.
Additional resources:
How to enable HTTPS for JupyterHub
Enable Multiuser Environment
How to install additional packages
