
This section describes how to provision and connect to ‘Custom LLMs, Ready in Minutes with LLaMa Factory’ VM solution on GCP.
Open Custom LLMs, Ready in Minutes with LLaMa Factory listing on GCP Marketplace.
Click Get Started.
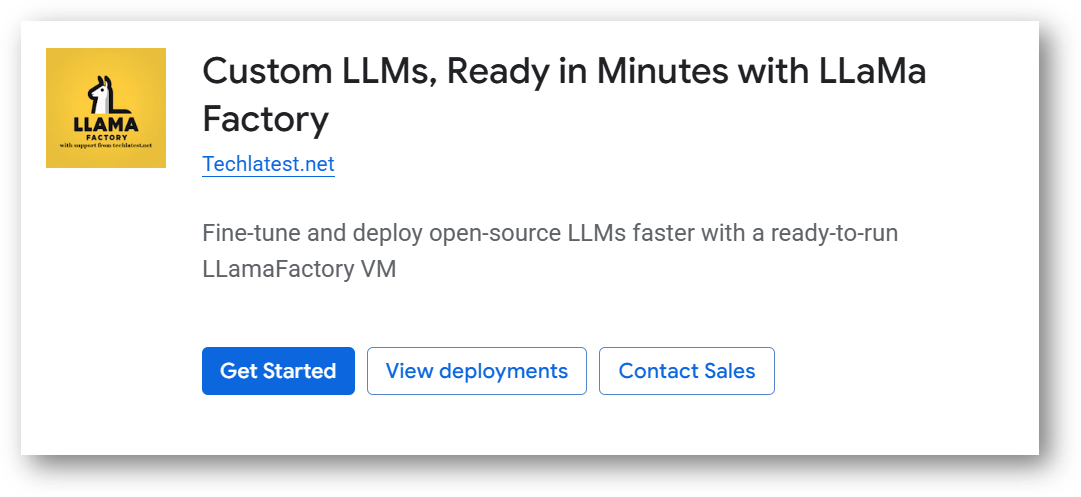
It will ask you to enable the API’s if they are not enabled already for your account. Please click on enable as shown in the screenshot.
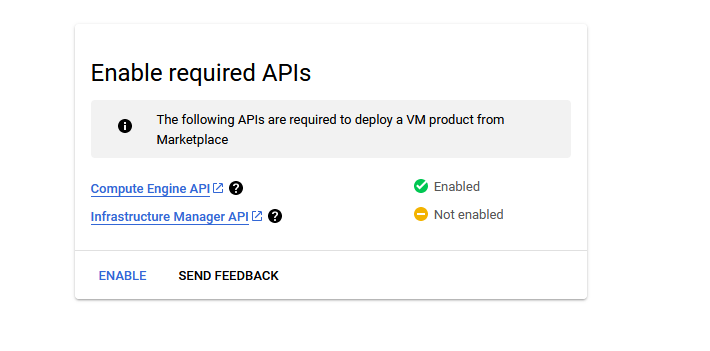
It will take you to the agreement page. On this page, you can change the project from the project selector on top navigator bar as shown in the below screenshot.
Accept the Terms and agreements by ticking the checkbox and clicking on the AGREE button.
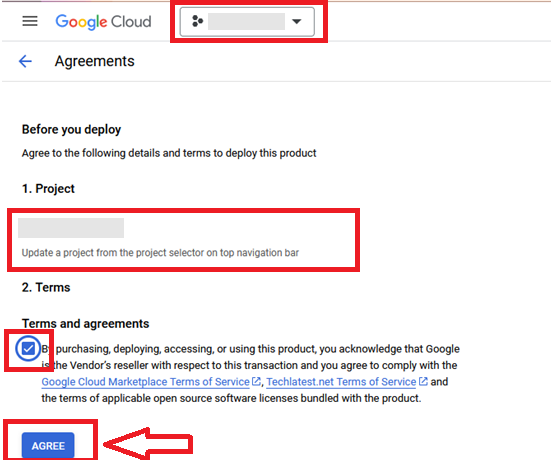
It will show you the successfully agreed popup page. Click on Deploy.
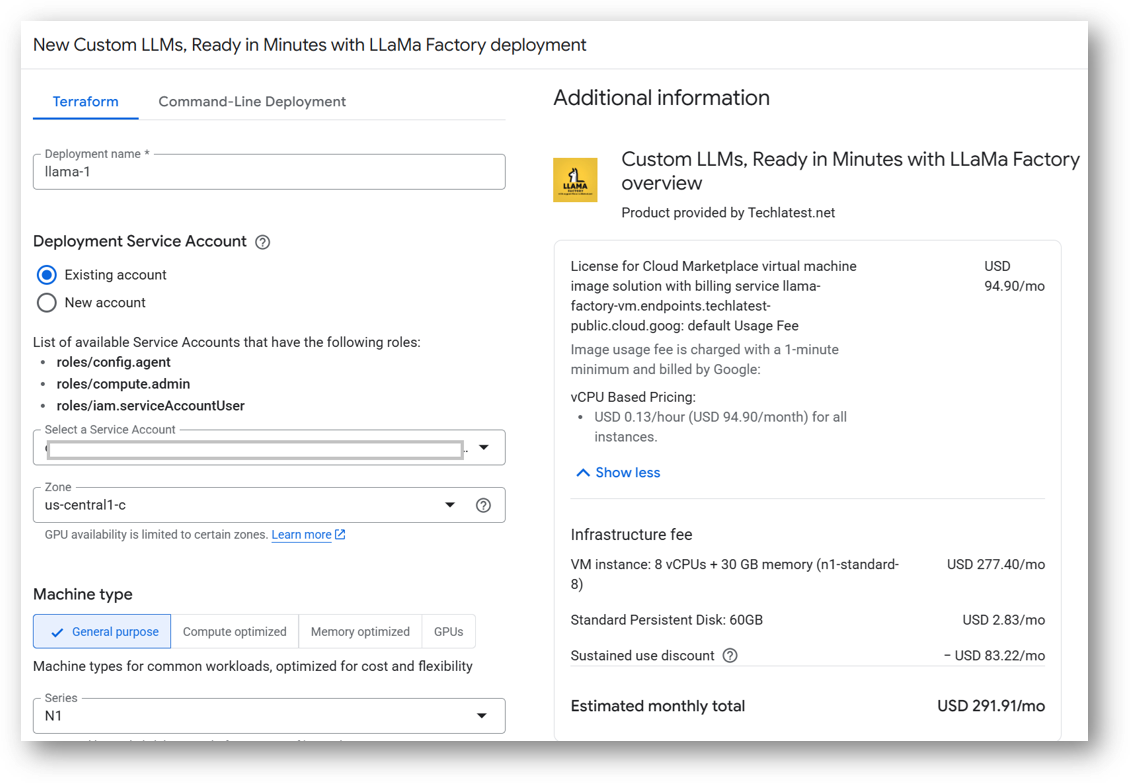
On deployment page, give a name to your deployment.
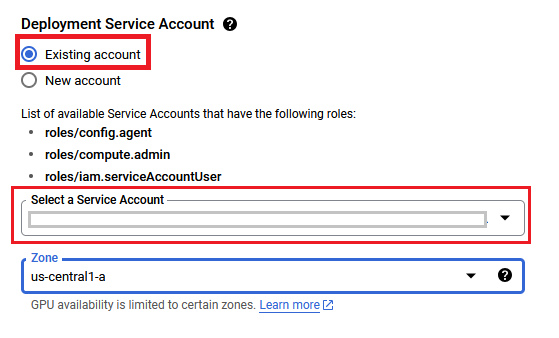
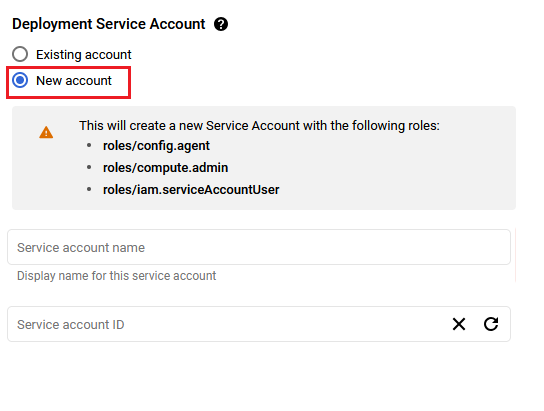
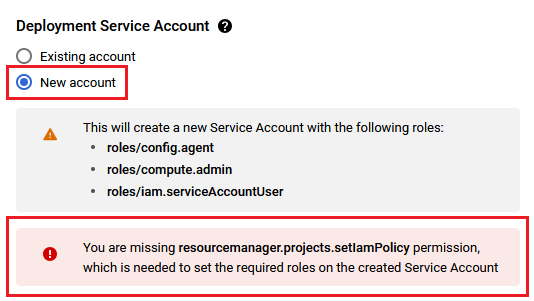
You are missing resourcemanager.projects.setIamPolicy permission, which is needed to set the required roles on the created Service Account
Select a zone where you want to launch the VM(such as us-east1-a)
Optionally change the number of cores and amount of memory. ( This defaults to 8 vCPUs and 30 GB RAM)
Minimum VM Specs : 30GB Memory /8vCPU
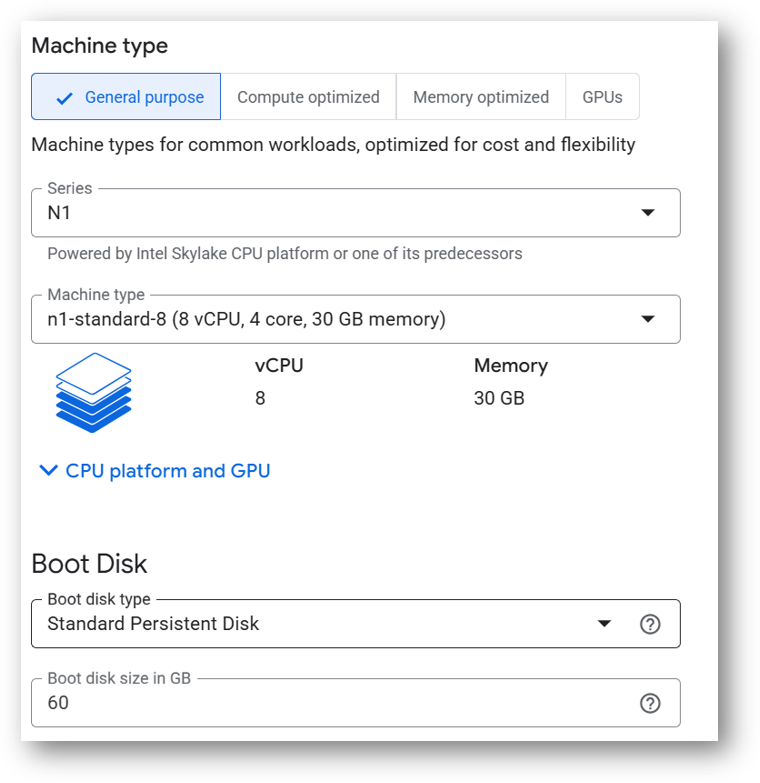
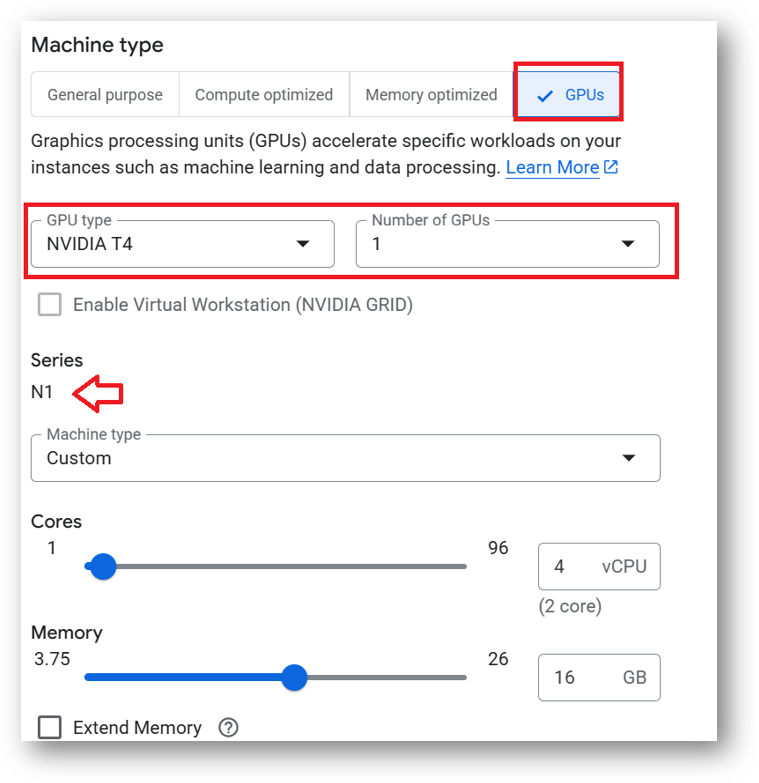
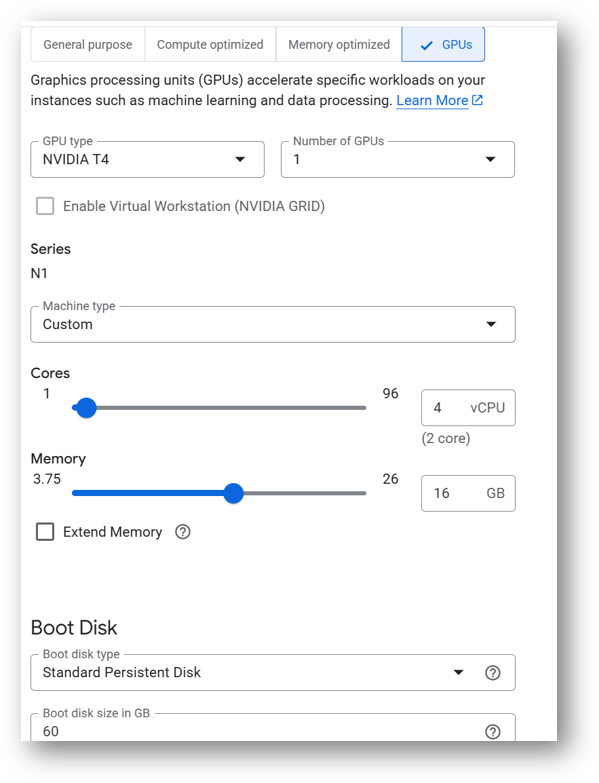
This VM can also be deployed using an NVIDIA T4 GPU instance to train faster. To deploy the VM with a GPU, click on the GPU tab as shown in below screenshot and select a NVIDIA T4 GPU instance. Please note that GPU availability is limited to specific regions, zones, and machine types. If you do not see a GPU option for your selected region, zone, or machine type, try adjusting those settings to find available configurations.
Optionally change the boot disk type and size. (This defaults to ‘Standard Persistent Disk’ and 60GB respectively)
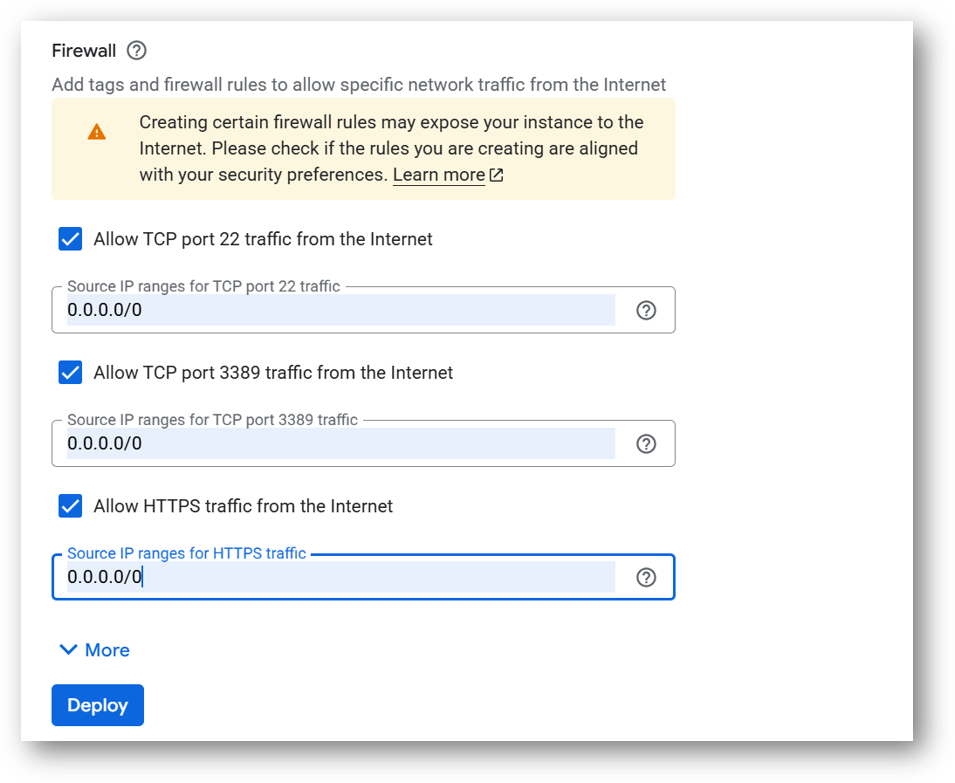
Optionally change the network name and subnetwork names. Be sure that whichever network you specify has ports 22 (for ssh), 3389 (for RDP) and 443 (for HTTPS) exposed.
Click Deploy when you are done.
Custom LLMs, Ready in Minutes with LLaMa Factory will begin deploying.
A summary page displays when the compute engine is successfully deployed. Click on the Instance link to go to the instance page .
On the instance page, click on the “SSH” button, select “Open in browser window”.
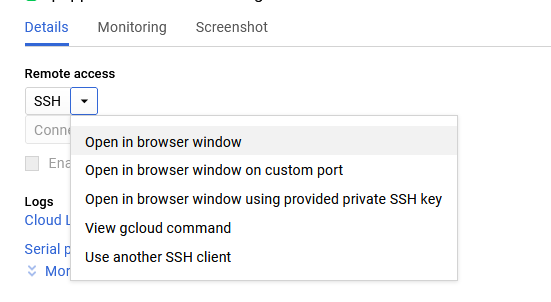
sudo su ubuntu
cd /home/ubuntu/
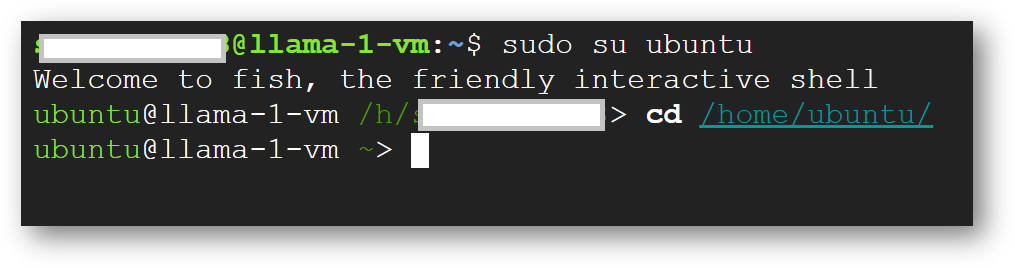
sudo passwd ubuntu
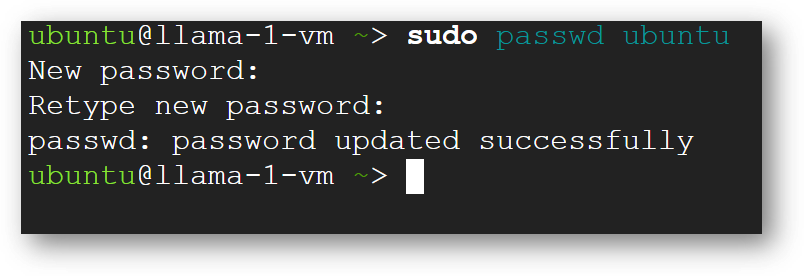
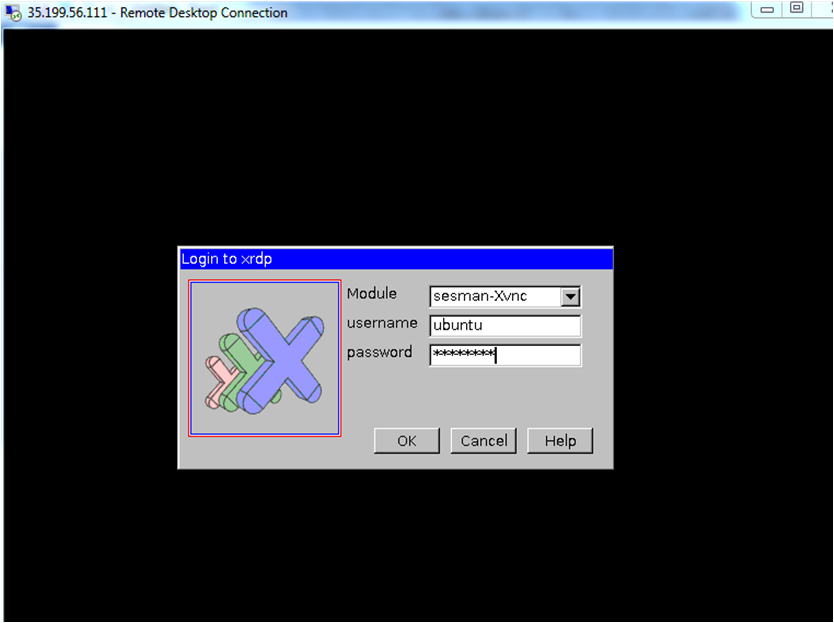
Now the password for ubuntu user is set, you can connect to the VM’s desktop environment from any local windows machine using RDP or linux machine using Remmina.
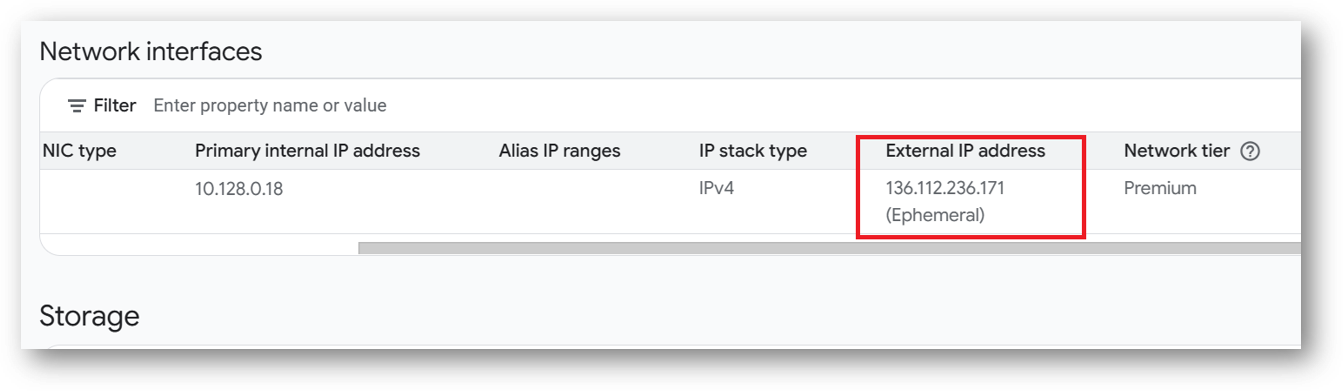
To connect using RDP via Windows machine, first note the external IP of the VM from VM details page as highlighted below
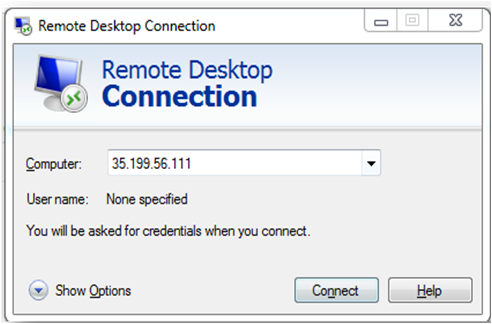
Then From your local windows machine, goto “start” menu, in the search box type and select “Remote desktop connection”
In the “Remote Desktop connection” wizard, paste the external ip and click connect

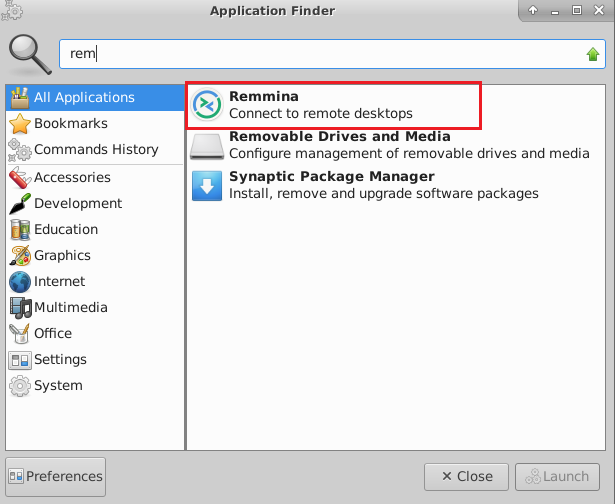
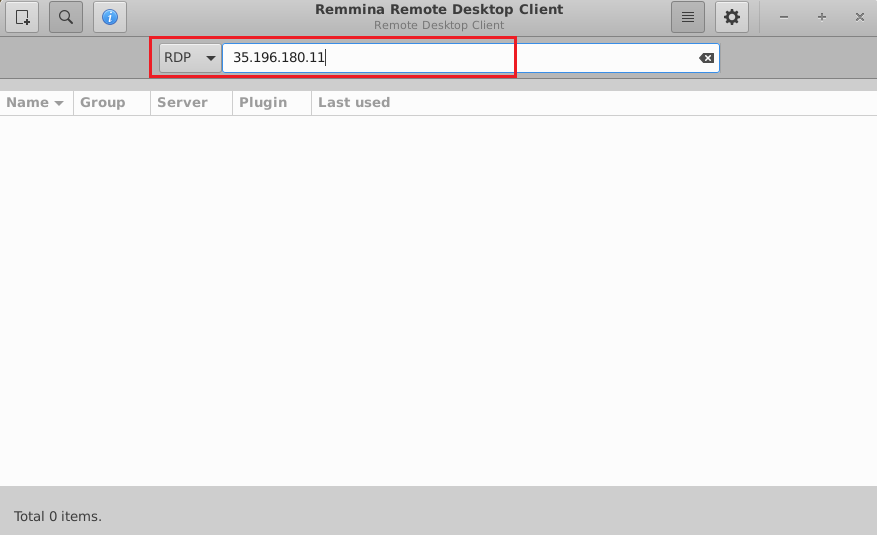
Note: If you don’t have Remmina installed on your Linux machine, first Install Remmina as per your linux distribution.
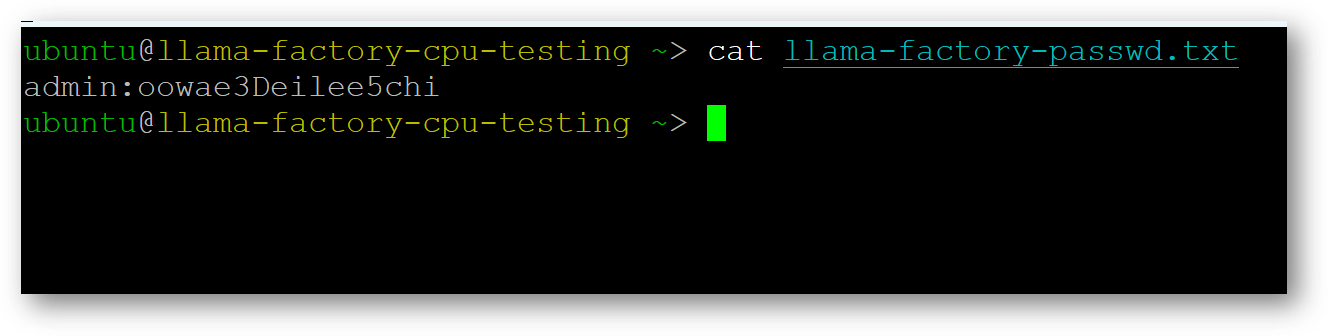
cat llama-factory-passwd.txt
Here username is admin with random password.
Browser will display a SSL certificate warning message. Accept the certificate warning and Continue.
Provide the ‘admin’ user and its password we got at step 14 above.
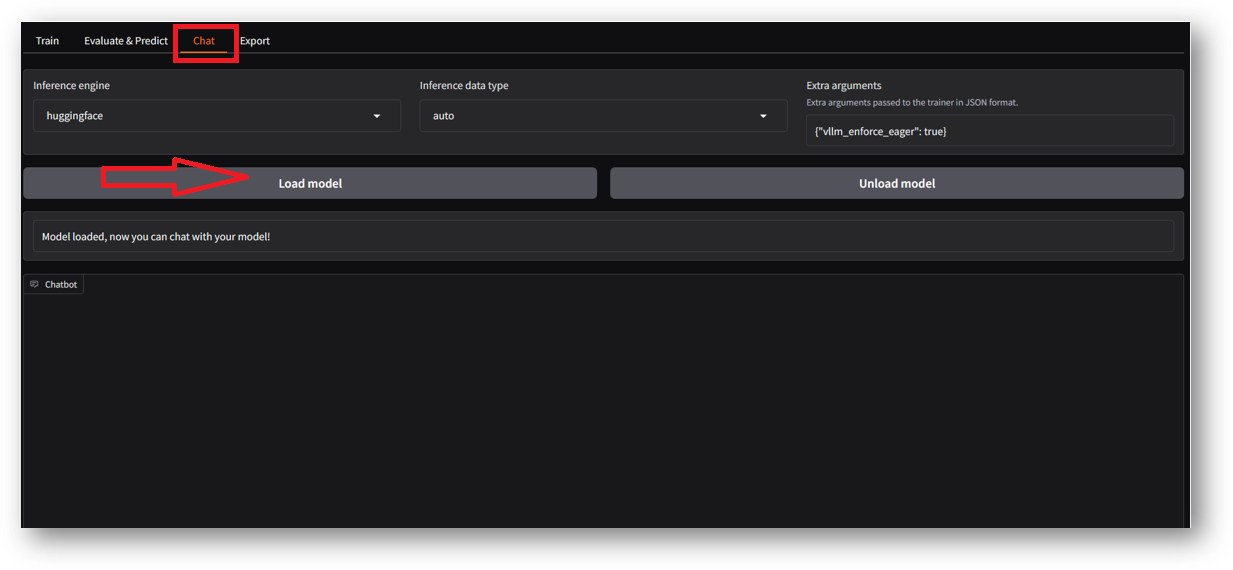
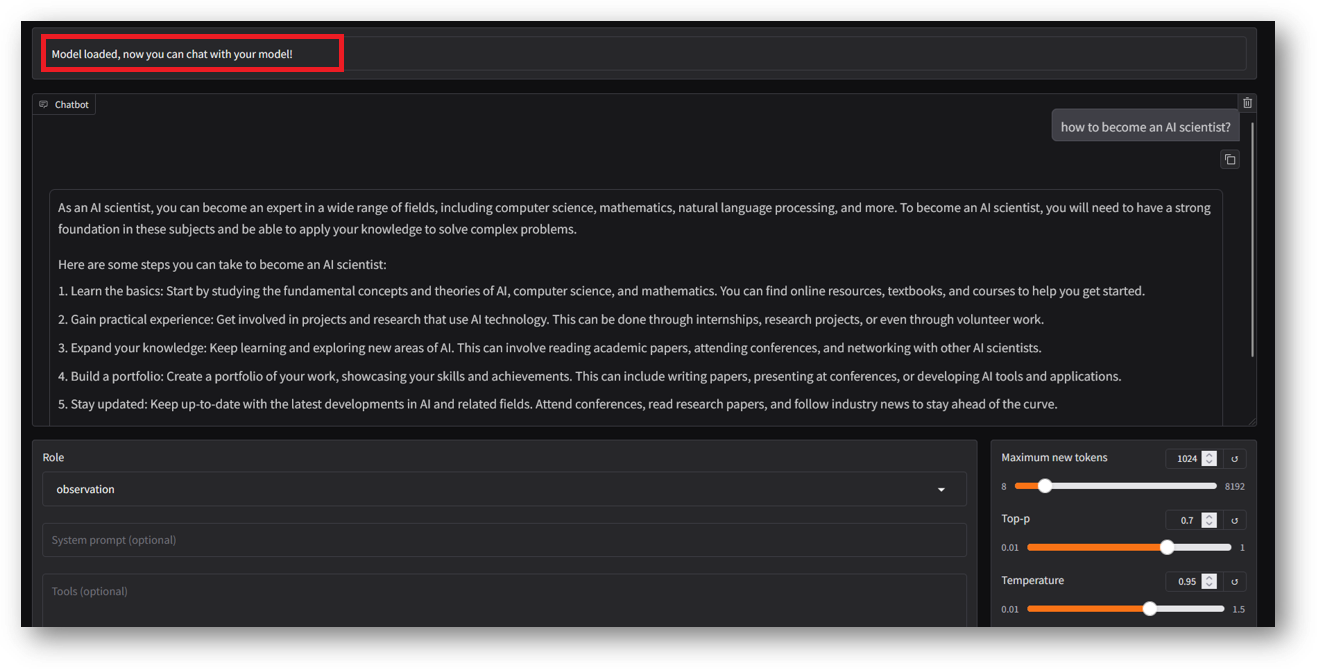
Now you are logged in to LLaMa Factory Web Interface. Here you can select different values and train/chat/evaluate the models.

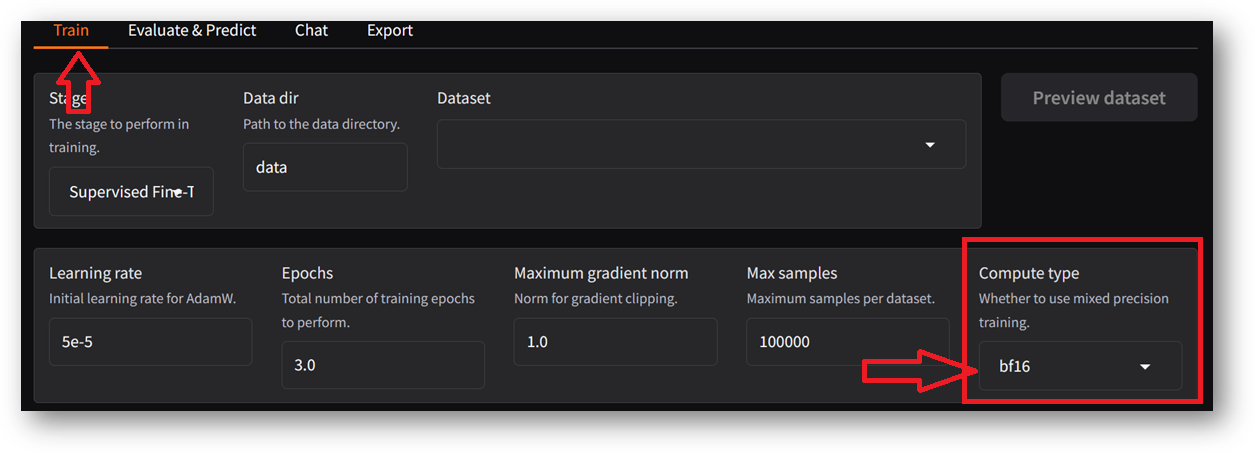
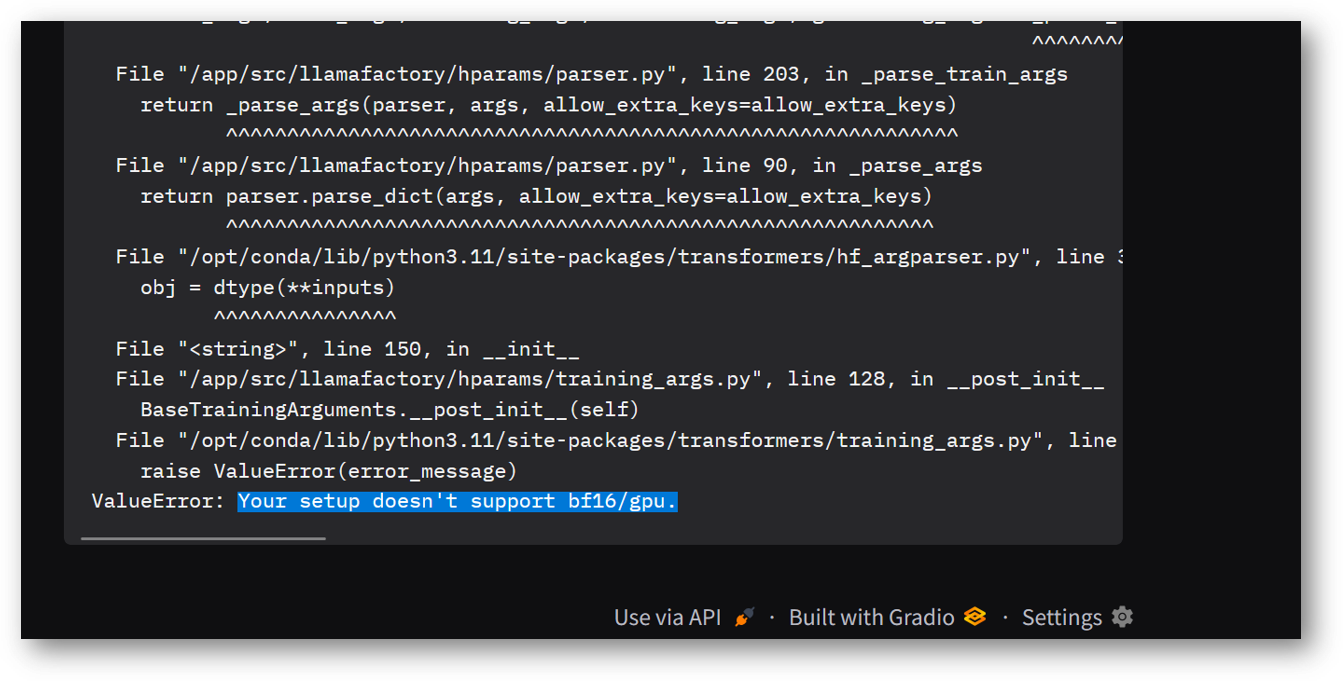
Note: If you are using CPU instance type then make sure to change the default value of Compute Type from bf16 to fp16 or fp32. If Training starts with the default value bf16 on CPU instance then it will show an error message “Your setup doesn’t support bf16/gpu”. Also CPU instances will take much longer to finish the training compared to GPU instances.
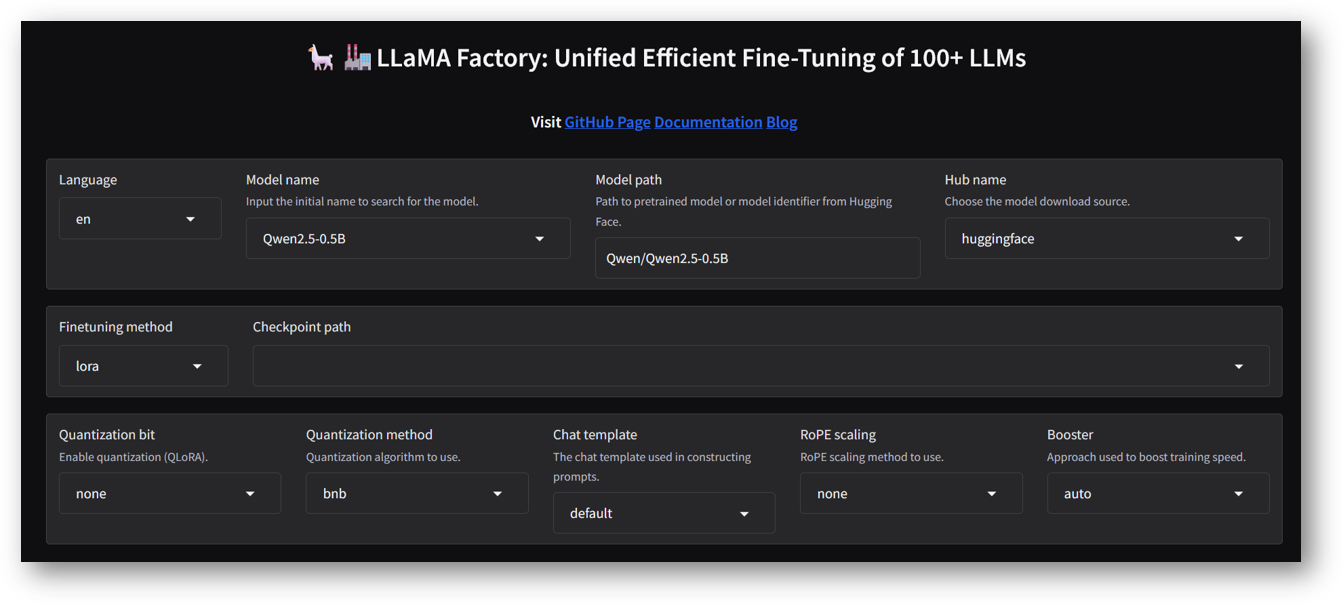
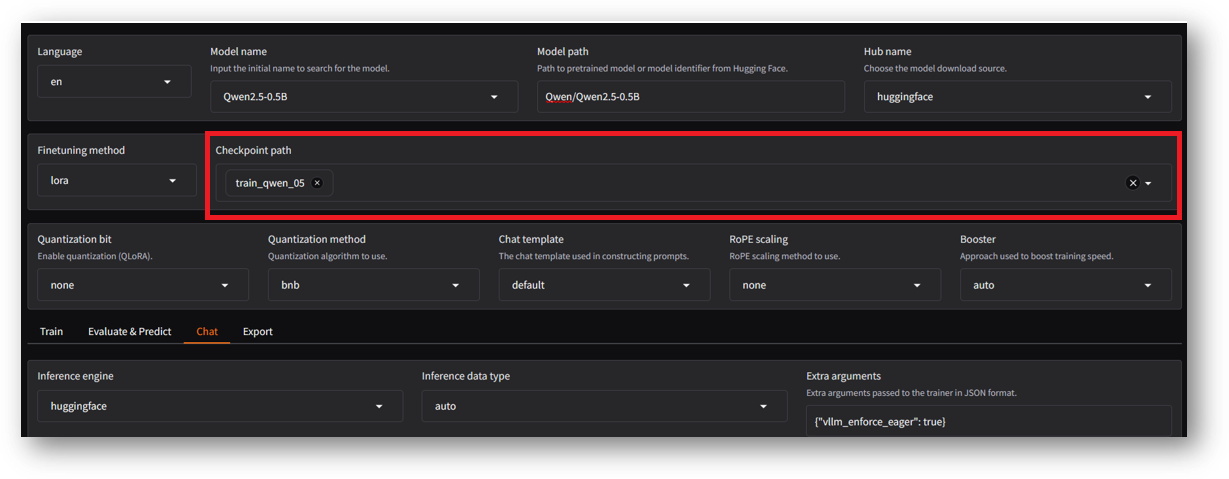
Model name: Qwen2.5-0.5B-Instruct
Hub name: huggingface
Finetuning method: LoRA
Dataset: identity, alpaca_en_demo
Compute type: fp16 (for cpu instace) / bf16 (for gpu instance)
Output dir: train_qwen_05 (Any name of your choice)
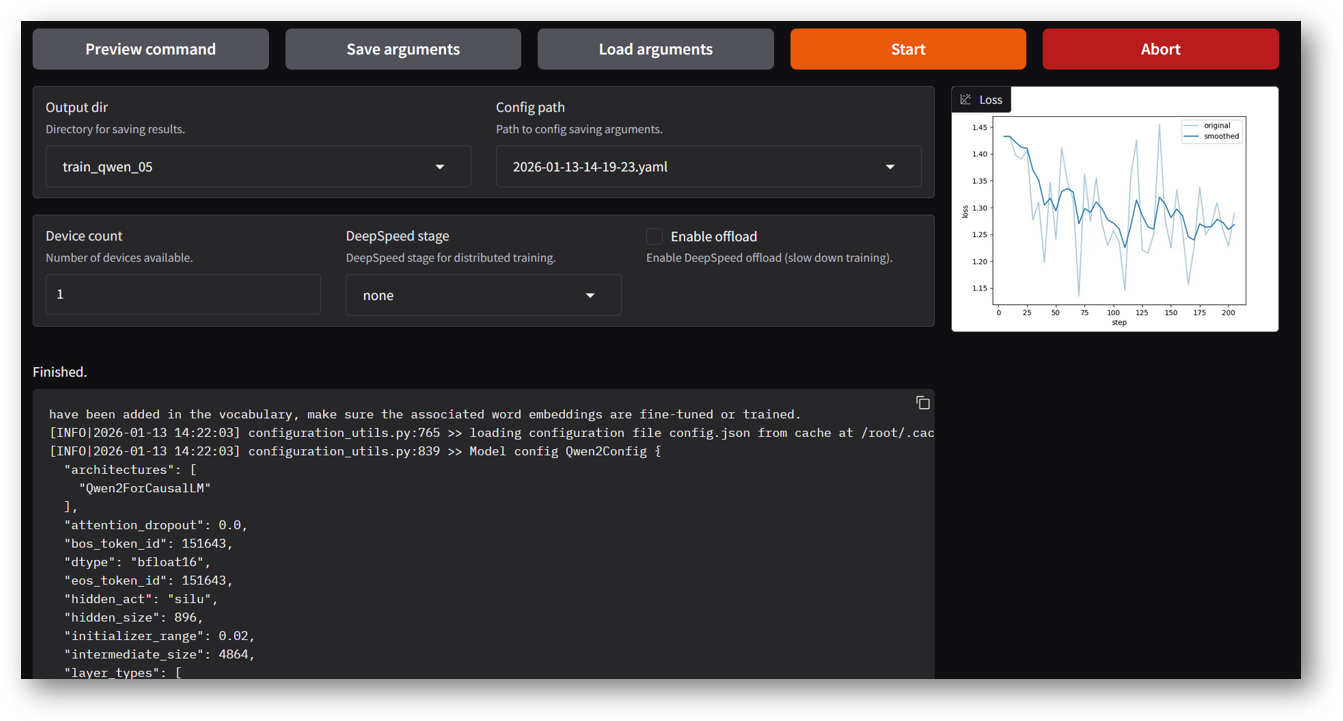
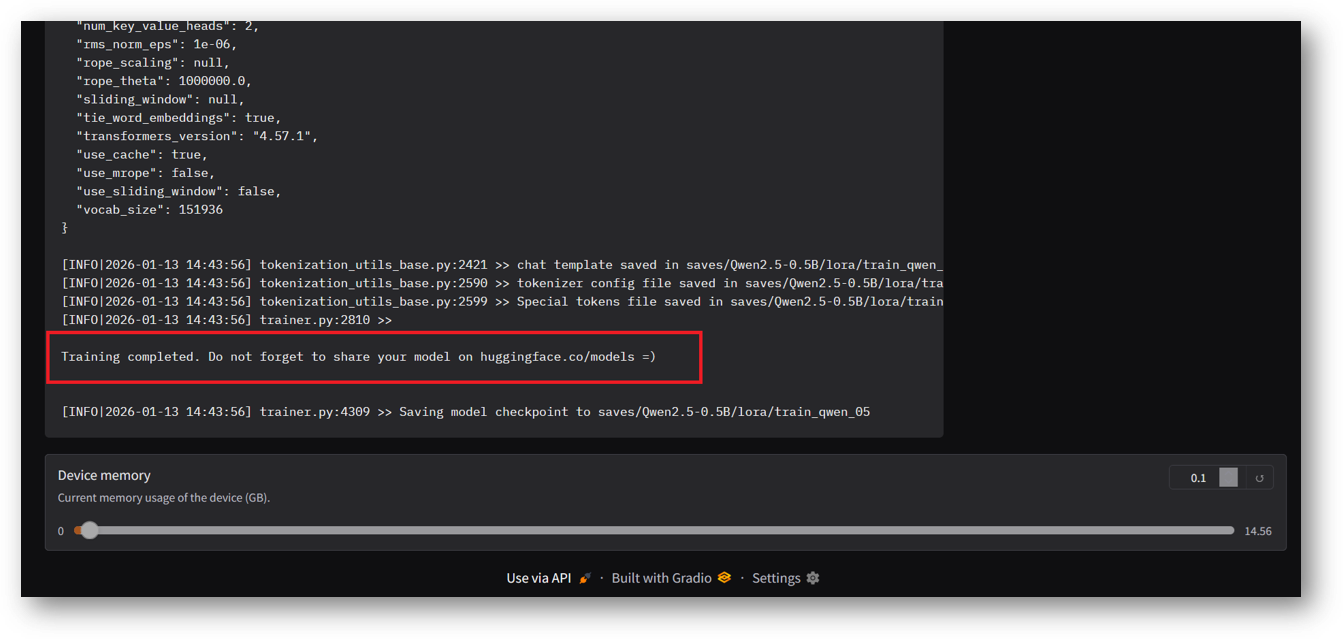
Once training completed you will see below successful message in the logs window.
sudo docker exec -it llamafactory /bin/bash
sudo docker ps -a

If you see the container is not running and in Exited state then restart it with
sudo docker start llamafactory
lmf as a shortcut for llamafactory-cli.
For more details, please visit Official Documentation page