
This section covers how to troubleshoot and fix common errors while running Open WebUI using Nginx proxy via HTTPS in your local Browser.
Note: Please check our Getting Started Guide pages to learn how to deploy and connect to the ‘DeepSeek & Llama-powered All-in-One LLM Suite’ solution via terminal, as well as how to access the Open WebUI interface. Alternatively, check the GPU-supported DeepSeek & Llama-powered All-in-One LLM Suite if you are using a GPU-based alternative of the same offer.
A. SyntaxError: JSON.parse: unexpected character at line 1 column 1 of the JSON data or Network Error
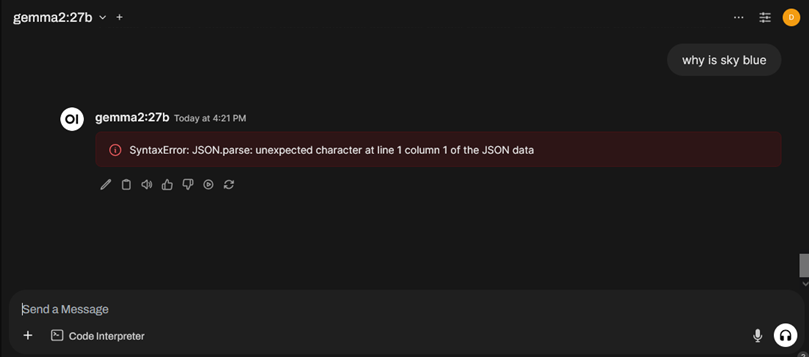

If you are encountering JSON.parse error or Network Error then follow below steps to fix it.
sudo vi /etc/nginx/sites-available/default

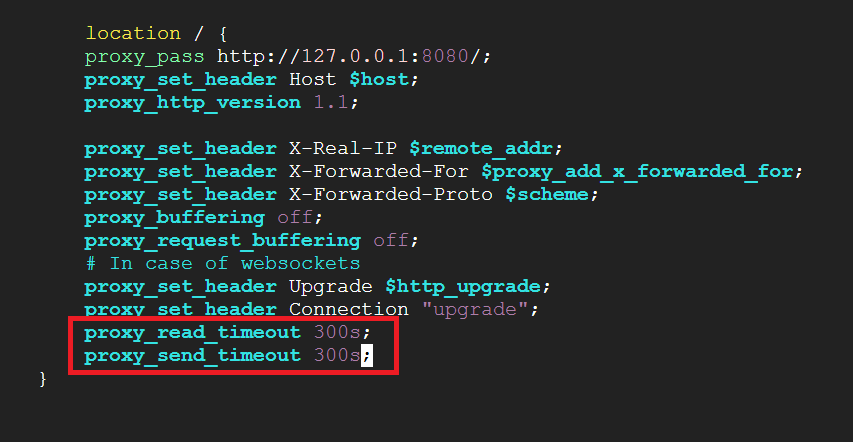
Press ‘i’ to enable insert mode. In the “location” section add below parameters and save the changes by pressing ESC key followed by :wq
proxy_read_timeout 300s;
proxy_send_timeout 300s;
The file should match the format shown in the screenshot below.
B. 500: Ollama: 500, message=‘Internal Server Error’, url=‘http://127.0.0.1:11434/api/chat’
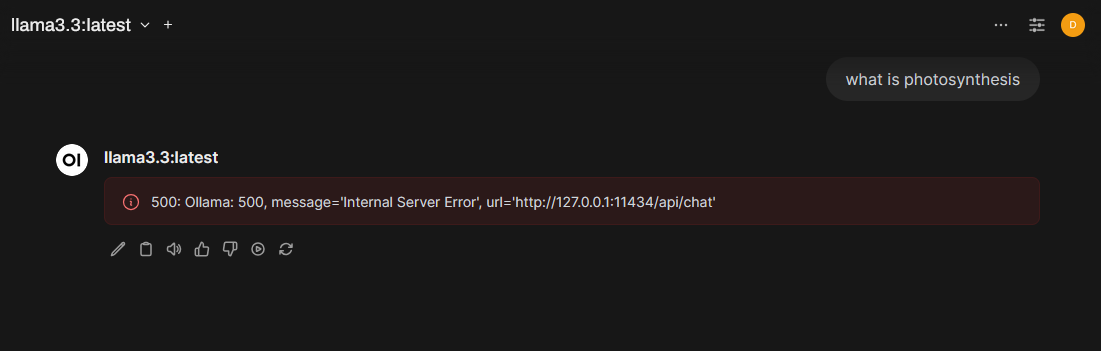
If you encounter the error “500 Internal Server Error” in OpenWebUI, it means that the loaded model requires more RAM than what is currently available.
To determine how much RAM is needed, you can run the following command in the terminal:
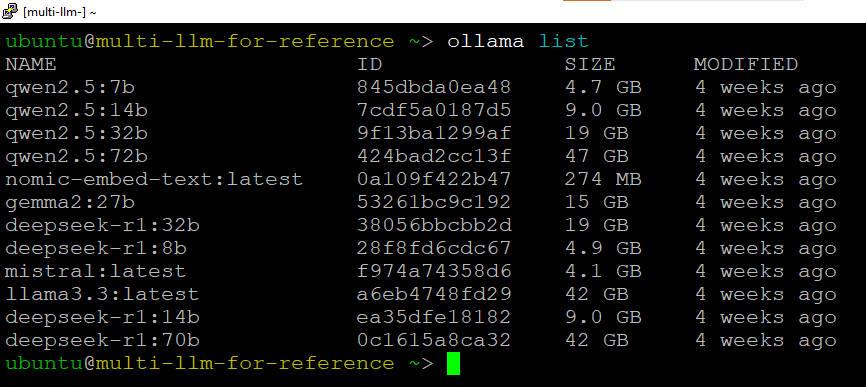
check the name of the available models -
ollama list
Run the model using -
ollama run modelname
This will display the required memory for the model. If the available RAM is insufficient, updating your existing instance to a higher RAM instance type should resolve the issue.

C. Multiple models are loaded in the memory
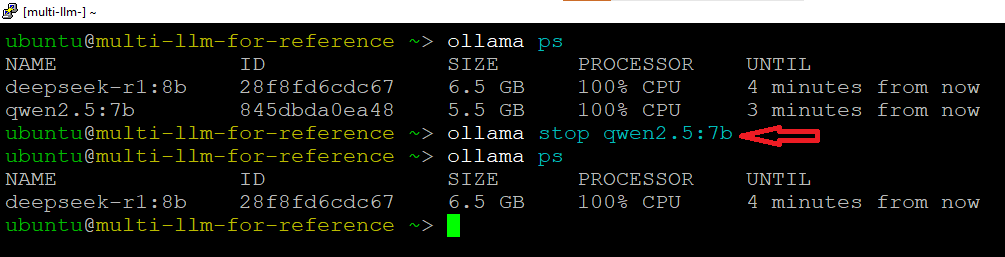
ollama ps

ollama stop modelname
Few commands to troubleshoot the issue and check the logs:
journalctl -fu Ollama
sudo docker logs open-webui --follow
journalctl -fu nginx
free -h
watch -n 1 nvidia-smi