
This section describe Ollama API Usage and its examples.
The Ollama API offers a rich set of endpoints that allow you to interact with and manage large language models (LLMs) on your local machine. This section covers some of the key features provided by the Ollama API, including generating completions, listing local models etc.
To generate a completion with a specified model and prompt, use the POST /api/generate endpoint. This is a streaming endpoint, so the response might contain a series of JSON objects.
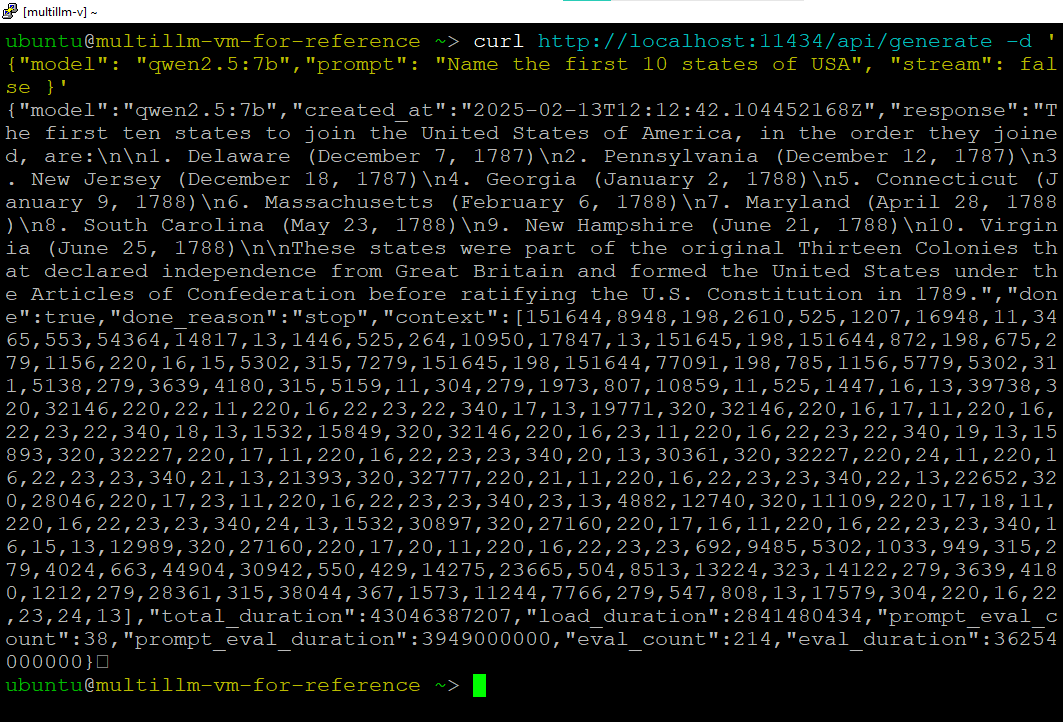
Generate Request can be made like below: To receive the response in one reply, you can set stream to false:
e.g
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b",
"prompt": "Name the first 10 states of USA",
"stream": false
}'
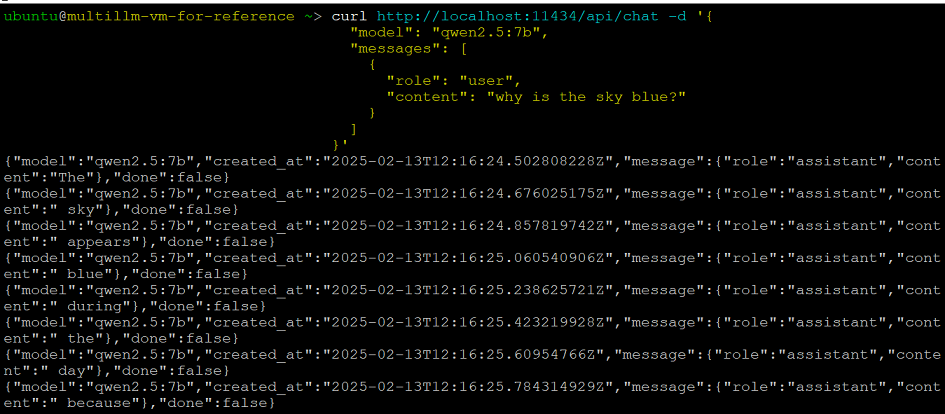
Chat Request can be made as follows:
curl http://localhost:11434/api/chat -d '{
"model": "qwen2.5:7b",
"messages": [
{
"role": "user",
"content": "why is the sky blue?"
}
]
}'
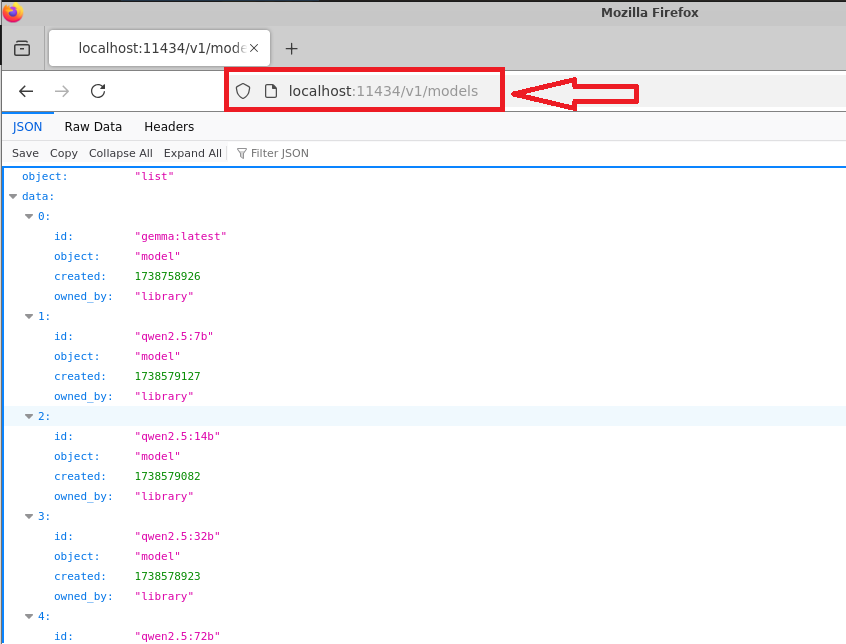
You can also access the API page from browser with localhost URL as “http://localhost:11434/v1/models”. To do so connect via RDP/remmina session, open Firefox browser from the desktop. Provide “http://localhost:11434/v1/models” in the browser and hit enter.
To get specific model use http://localhost:11434/v1/models/modelname.
e.g http://localhost:11434/v1/models/qwen2.5:7b
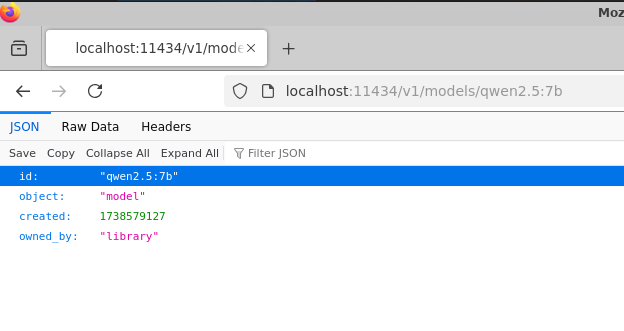
Watch the headers of this from the header tab.
For more details, please visit Official Documentation page